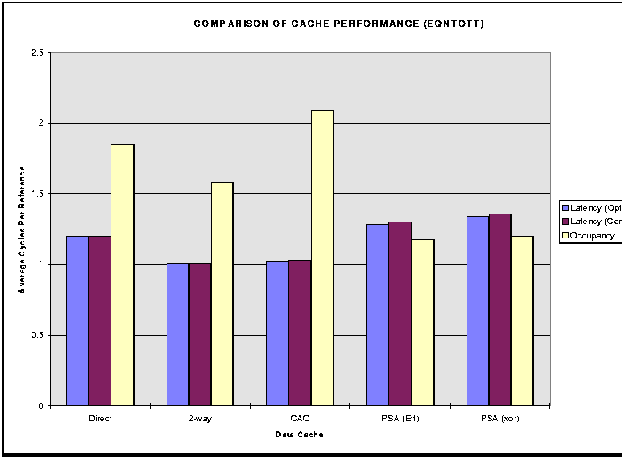
Cache access laterncy is defined to be the average time the processor must wait for a memory reference to be resolved. And the average cache occupancy is the time the cache is busy for each reference [1]. A smaller access latency and smaller occupancy is preferred in a cache. If the latency is high, the processor must stall, waiting for data. If the occupancy is high, there is a greater chance outstanding references will conflict with newly issued references. As is seen from the simulation results, most of the caches have the same access latency, and are differentiated by their cache occupancy.
Different hit rates for loads and stores are recorded and for the no-write
allocated write policy, the following parameters are used as in [1].
The sequential associative caches, CA cache and PSA cache, further divide
the hit rate H into hits that are detected on the first cache probe ![]() and those detected on the second probe
and those detected on the second probe ![]() . The sequential caches
use the rehash bit to avoid a second cache probe for some misses and so, the
Miss rate M is divided into
. The sequential caches
use the rehash bit to avoid a second cache probe for some misses and so, the
Miss rate M is divided into ![]() , denoting misses detected on the
first probe, and
, denoting misses detected on the
first probe, and ![]() , denoting misses detected on the second probe.
The following tables define certain parameters used in the timing model and the
values assumed for each of them in the model.
, denoting misses detected on the second probe.
The following tables define certain parameters used in the timing model and the
values assumed for each of them in the model.

The Timing Equations used to compute Cache Access Latency are:
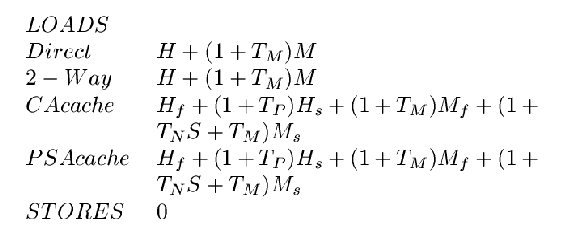
The Timing Equations used to compute Cache Occupancy Time are:
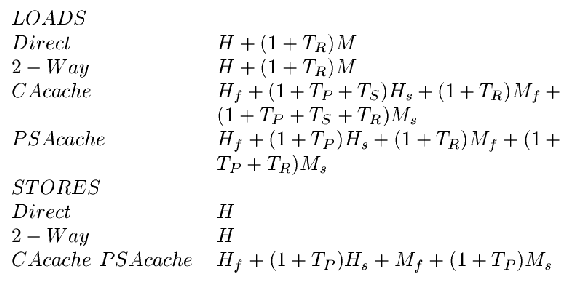
Figure 1: ``Comparison of Performance for compress benchmark''
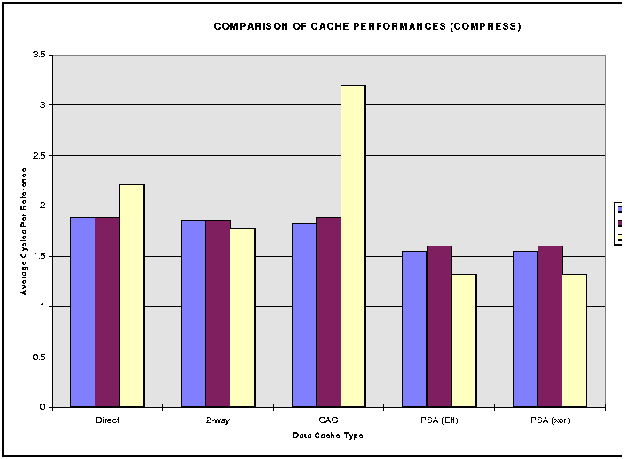
Figure 2: ``Comparison of Performance for eqntott benchmark''